
아래의 상기 내용은
"혼자공부하는 SQL"의 도서 내용과 인터넷의 내용을 실습 및 정리한 글입니다.
1.인덱스(index)
1)정의
-인덱스란 데이터를 빠르게 조회할 수 있게 하는 기술 혹은 자료구조.
-데이터에 순번을 붙여 데이터가 어디에 위치하는지 나타내는 주소같은 역할을 한다.

2.인덱스의 장단점
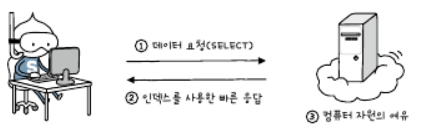
1)장점
- 빠른 응답속도를 얻을 수 있다.
- 기존보다 적은 처리량과 향상된 속도로 시스템 성능을 올릴 수 있다.
2)단점
-인덱스도 하나의 데이터이기에 추가적인 용량이 발생한다.
-처음 인덱스 생성에 많은 시간이 필요로 할 수 있고 조회가 아닌 제거,수정같은 작업에
추가적인 시간이 필요해질 수 있다.
3.인덱스의 종류
1)클러스터형 인덱스(Clustered Index)
-데이터에서 행의 순서가 인덱스에서 행의 순서에 대응하는 인덱스.
-기본 키(PRIMARY KEY)가 생성될 때 자동 생성되며 정렬도 자동으로 된다.

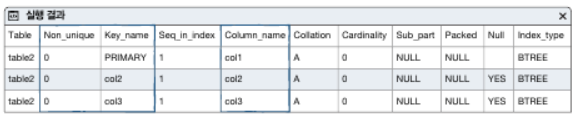
-Column_name이란 부분에 col1이 설정되어있다는 뜻은 col1에 인덱스가 설정되어있다는 뜻.
-Non_unique는 중복을 허용하는지 고유하는지를 나타내고 0은 False 1은 True로 현재는 중복이
허용되지않는 인덱스이다.
-col2,col3에 UNIQUE 키워드를 넣음으로써 보조 인덱스를 설정할 수 있다.
2)보조 인덱스(Secondary Index)
-데이터에서 행의 순서에 관계없이 부여할 수 있는 인덱스.
-UNIQUE 키워드를 사용하여 고유키를 부여할 수 있다.
-


'데이터베이스 > 혼자공부하는 SQL' 카테고리의 다른 글
| 07-01 스토어드 프로시저 (0) | 2024.05.19 |
|---|---|
| 06-02 균형트리 (0) | 2024.04.01 |
| 05-03 가상의 테이블 : 뷰 (1) | 2024.03.19 |
| 05-02 제약조건 (0) | 2024.03.09 |
| 05-01 테이블 생성 및 입력 (1) | 2024.02.28 |